Claude 3 vs GPT-4 世界最强模型全面对比评测 | 智图派


话说 GPT-4 已经被超越很多回了,这次 Claude 3 发布号称全面超越 GPT-4 的模型 Opus,口说无凭,今天我们不看别人怎么说,咱们就来亲手评测一下,最后,再来回答一个问题,Claude Pro 和 ChatGPT Plus 都是 20 美元,那么如果我只有 20 美元,该买 哪一个呢?
本期测试从以下几个方面进行:
数学推理测试:使用同一道数学题对 GPT-4、Opus 和 Gemini Advanced 分别进行测试,结果 GPT-4 出现了很蹊跷的一幕。
代码测试:编写 Python 代码处理视频字幕文本,结果还挺意外的。
大海捞针测试,在我的字幕文件中进行大海捞针测试,结果很有趣,值得单出一期视频来详细说说。
图像识别,简单地预测比特币趋势。看到结果的第一眼我以为我把模型给弄反了。
经典推理问题,这个结果让我有点小意外
最后是大招,视频脚本转文章,测试结果让我觉得 Opus 还是值得用的。
好,咱们先简单回顾一下 Glaude 3 官方文章的亮点。
Claude 3 系列亮点
Claude 3 系列包括三个最先进的模型,按能力递增的顺序分别是 Haiku、Sonnet 和 Opus
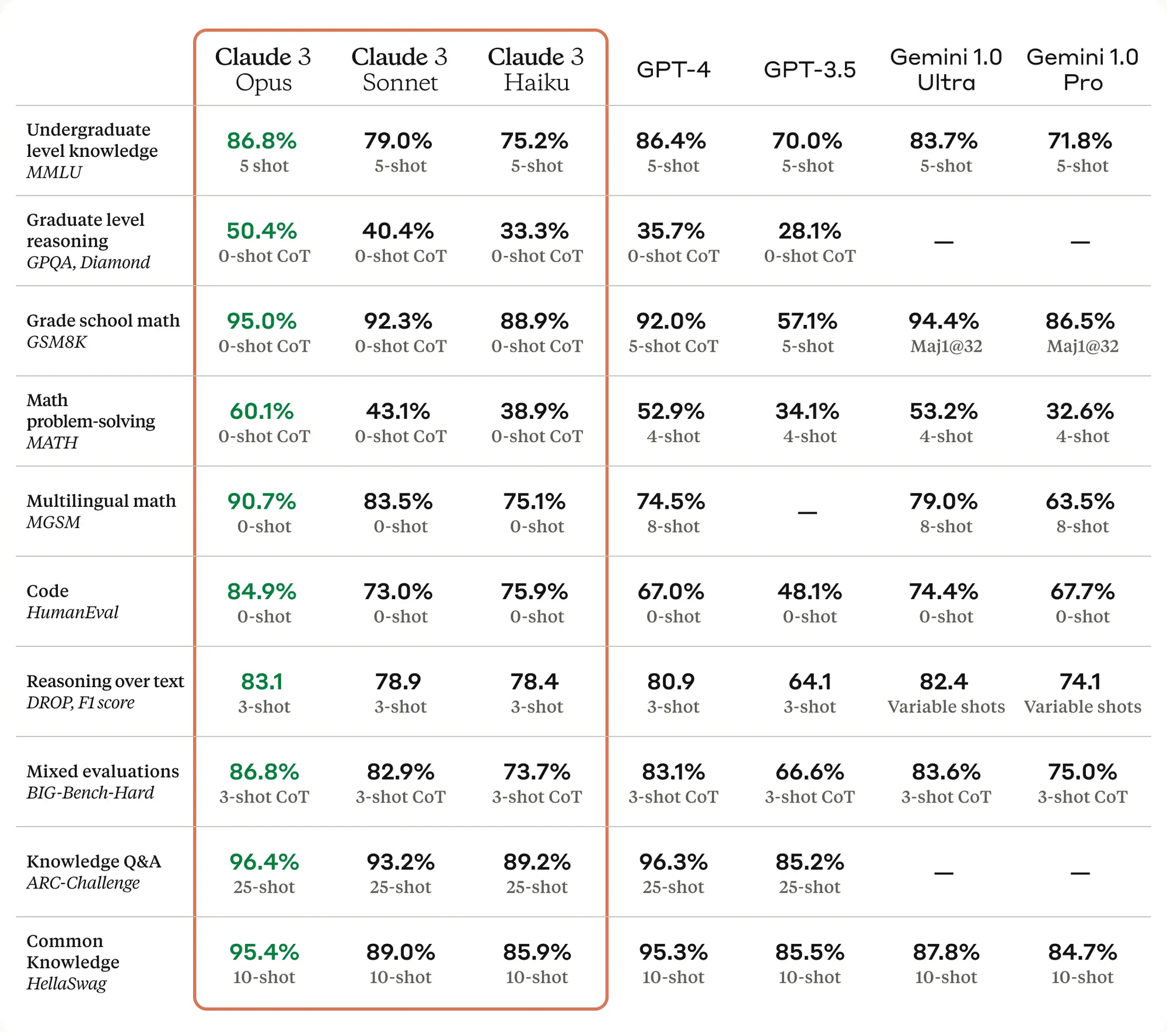
根据 Anthropic 的测试数据,Claude 3 的最强模型,Opus 在所有测试项目上,全面超越 GPT-4,等会我们主要对比的,就是这个模型。
Claude 3 系列模型的速度也得到了很大的提升,Sonnet 比 Claude 2 和 Claude 2.1 快 2 倍,Opus 的速度与 Claude 2 和 2.1 相似,但是能力却都有大幅提升,这点对企业用户来说更加关键。
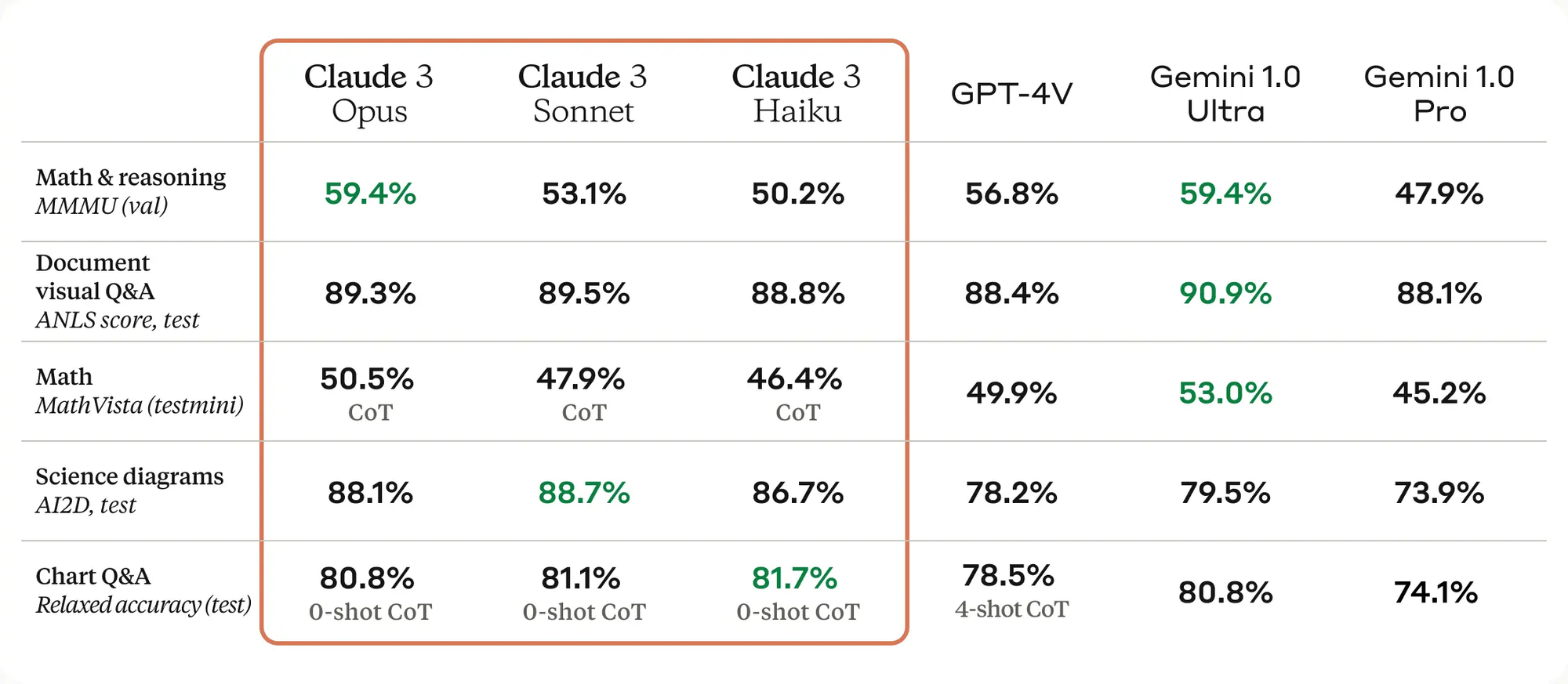
视觉能力也很能打,Opus 全面超越 GPT-4,两个指标上弱于 Gemini 1.0 Ultra,关键是 Claude 3 的三个模型视觉能力都不弱,尤其是在最后一项图表问答的测试中,0-Shot 思维链居然强于 GPT-4 的 4-Shot 测试,不了解 Shot 和思维链的,可以看下我的基础课程:
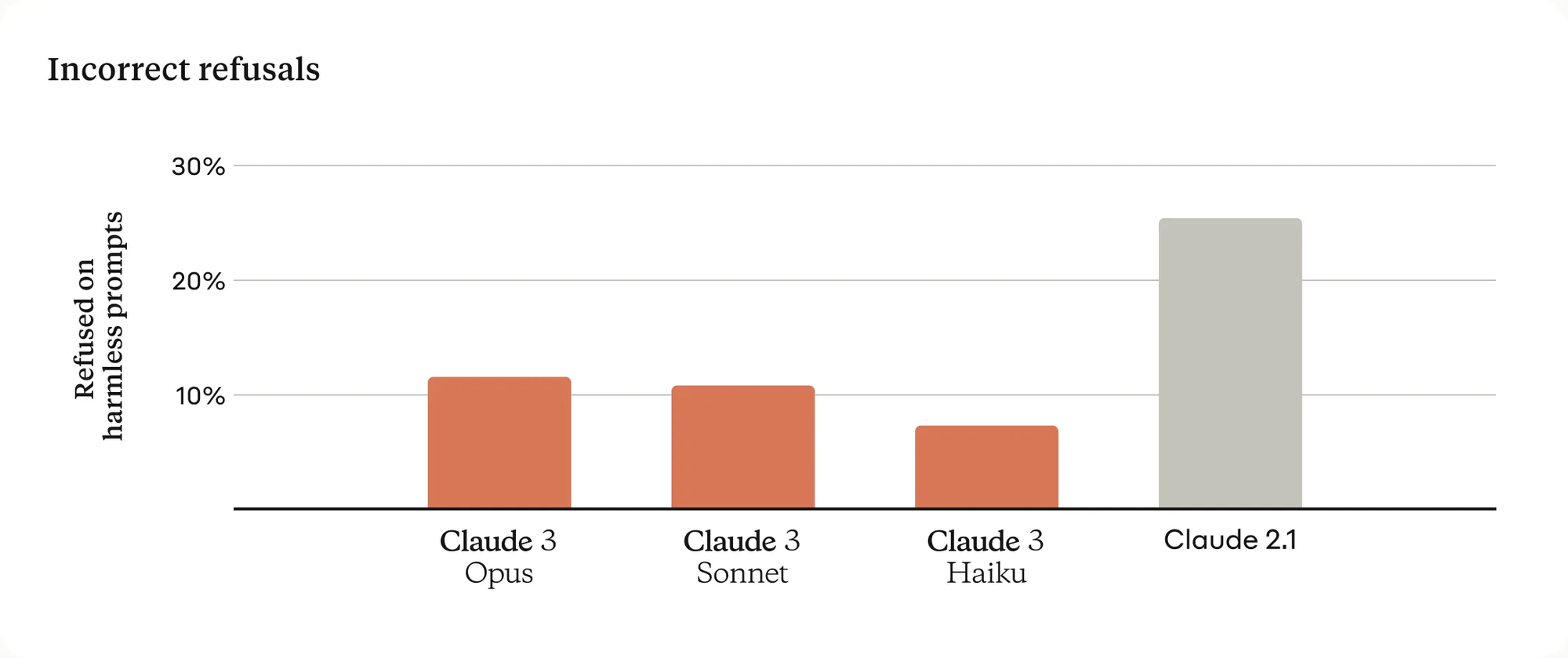
Claude 以前给大家的印象就是谨言慎行,经常拒绝回答问题,这次针对这个问题进行了改善,后面测试中我们也可以看到效果。
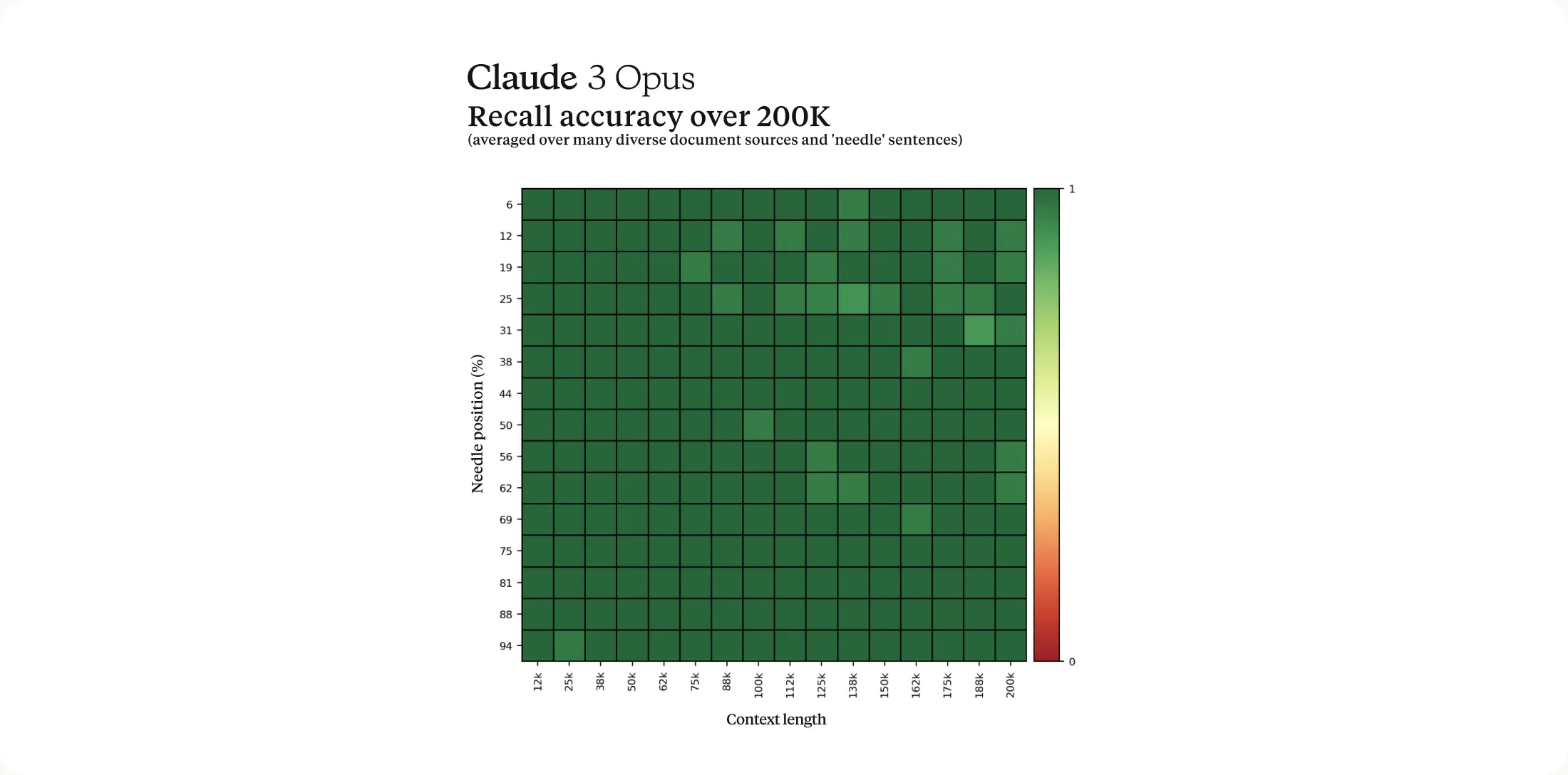
Claude 3 Opus 在大海捞针测试中,超过了99%的准确率,这点与 Gemini 1.5 Pro 的能力相当,Gemini 1.5 可以看我上期视频。但是 Claude 有一项很独特的表现,我在 Claude 2 发布的时候就注意到了,值得下期视频单独来讲讲。
与 GPT-4 的价格对比,大家都很体贴地把价格转换为百万 Token 了,看起来比以前几厘钱要顺眼很多。Opus 价格很贵,比 GPT-4 Turbo 贵不少,只比 GPT-4 32K 便宜。Sonnet 看来是目前比较实惠的选择。
| Model | Input Token Cost (per million) | Output Token Cost (per million) | Notes |
|---|---|---|---|
| Claude 3 Opus | $15 | $75 | Available with Claude Pro subscription; higher analytical skills, focus on image-text analysis |
| Claude 3 Sonnet | $3 | $15 | Expected to be at least 5x less expensive than Opus for the same data handling |
| Claude 3 Haiku | $0.25 | $1.25 | Not yet released; will be cheaper than GPT-3.5 Turbo |
| GPT-4 Turbo (128K) | $10 | $30 | Suitable for a wide range of applications |
| GPT-4 8K | $30 | $60 | - |
| GPT-4 32K | $60 | $120 | - |
| GPT-3.5 Turbo | $0.50 | $1.50 | Cheaper option within GPT series |
好,接下来我们进入测试环节。我目前是购买的 Poe 来使用 Claude Opus,因此也主要在 Poe 中对比测试 GPT-4,ChatGPT 仅作辅助说明。
AI 数学测试问题
这次测试中,同一个 GPT-4 模型,在两个不同的 APP 中,一个是 ChatGPT,一个是 Poe,结果表现的很蹊跷。
首先找了一道数学题,题目如下,前面两段主要是格式要求,问题是:
找出解决所提供数学问题的解答。答案是一个独特的数学表达式,使用LaTeX的\boxed{}指令呈现(例如:\boxed{4}或\boxed{3\pi})。格式说明:分数应以\frac{a}{b}的LaTeX形式表示(而非\frac12),不包含单位,平方根应以\sqrt{c}的LaTeX形式呈现(而非\sqrt2),所有空格和非关键的括号或格式化应被去除,有理数应呈现前导0。
提供由多个步骤组成的推理,每个步骤使用一行。推理步骤是一步连贯的数学推理,应在最多500个字符的一行内完整。如果答案是推理的一部分,则应在推理步骤中使用\boxed{}指令包含答案。不要使用\boxed{}指令表示除答案之外的任何内容。
问题:Amy、Ben和Chris的平均年龄是9岁。四年前,Chris的年龄与Amy现在的年龄相同。三年后,Ben的年龄将是那时Amy年龄的$\frac{2}{3}$。Chris现在多大年纪了?
以中文输出答案。
这道题的正确答案是 13
Opus
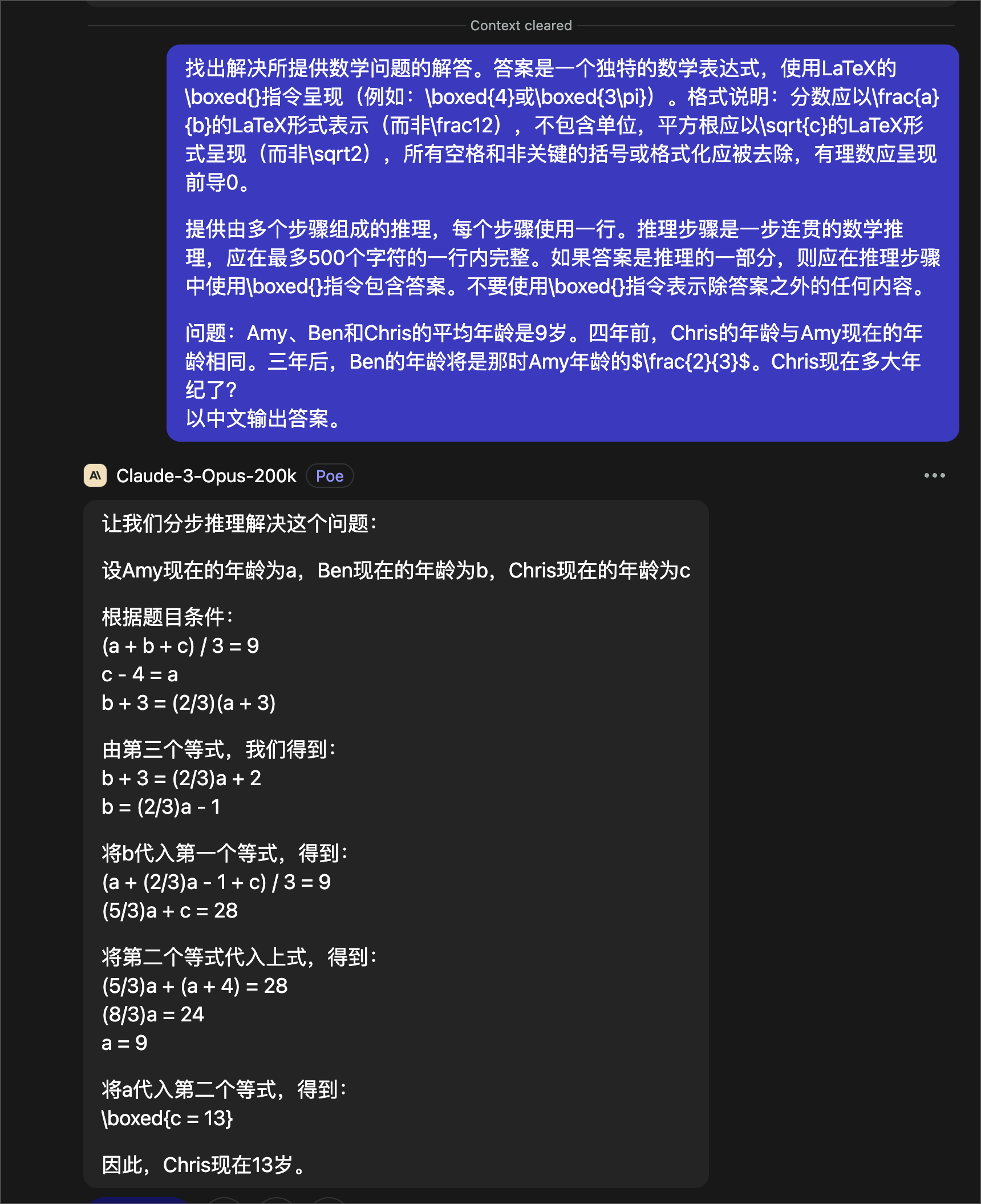
测试中,Claude 3 我用的都是 Opus 200K 的模型。我们先看 Opus 的结果:
正确地给出了解题的步骤,并且,结果也是正确的,13
GPT-4
再来看 GPT-4 的表现,Poe 中的 GPT-4 非常漂亮地完成了这道题,输出格式也是正确的 LaTeX 「LaTeX的发音可以是“Lah-tech”或“Lay-tech”,强调第一个音节。」
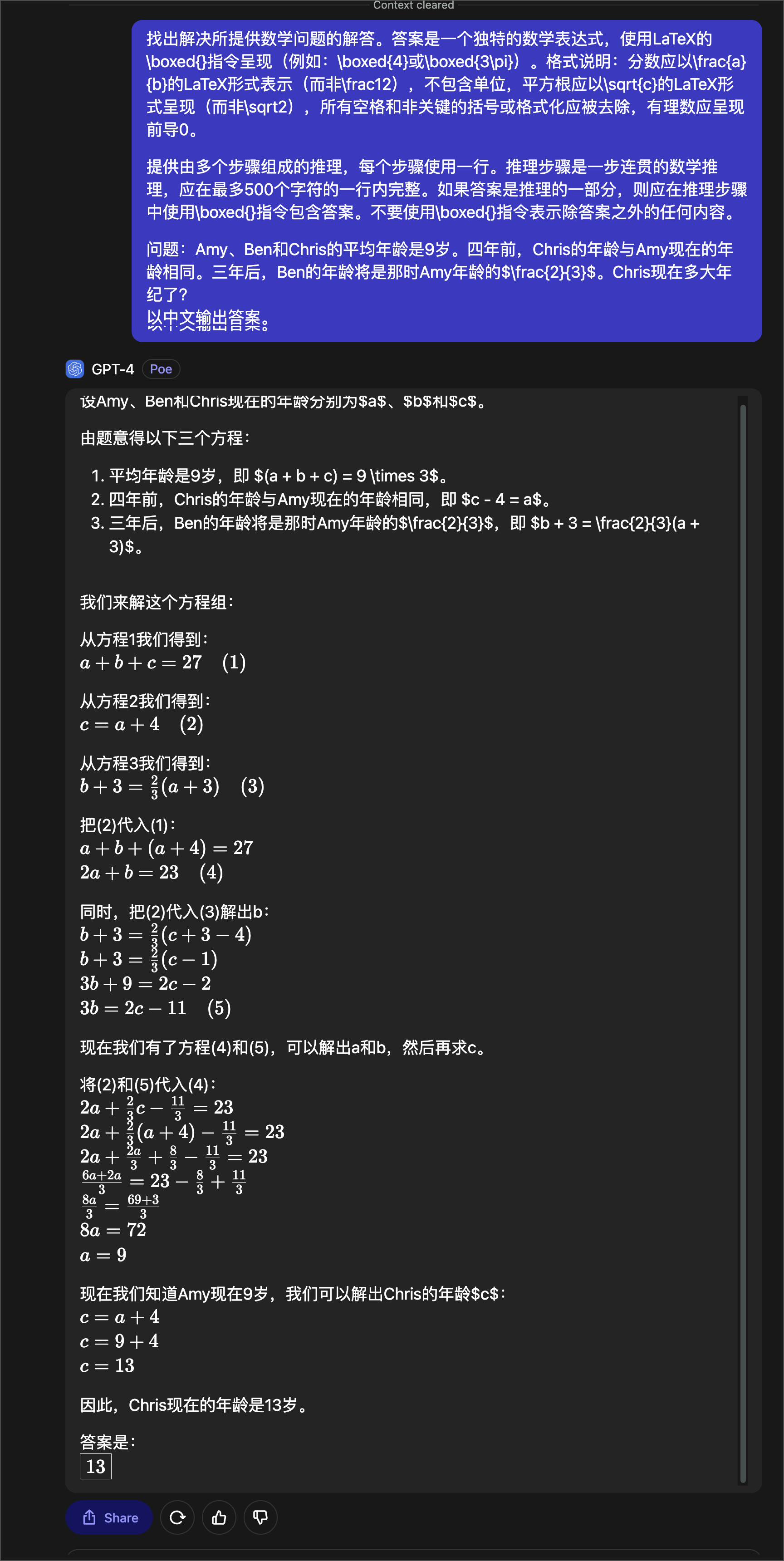
但是,在 ChatGPT 中的 GPT-4,却在解方程中出现了错误,最终给出了错误的答案 12.25

这结果很蹊跷,我以前使用的感觉,一直是同一个模型在 ChatGPT 中的表现会比 Poe 中的好那么一丢丢,现在看来真是事事无绝对啊。
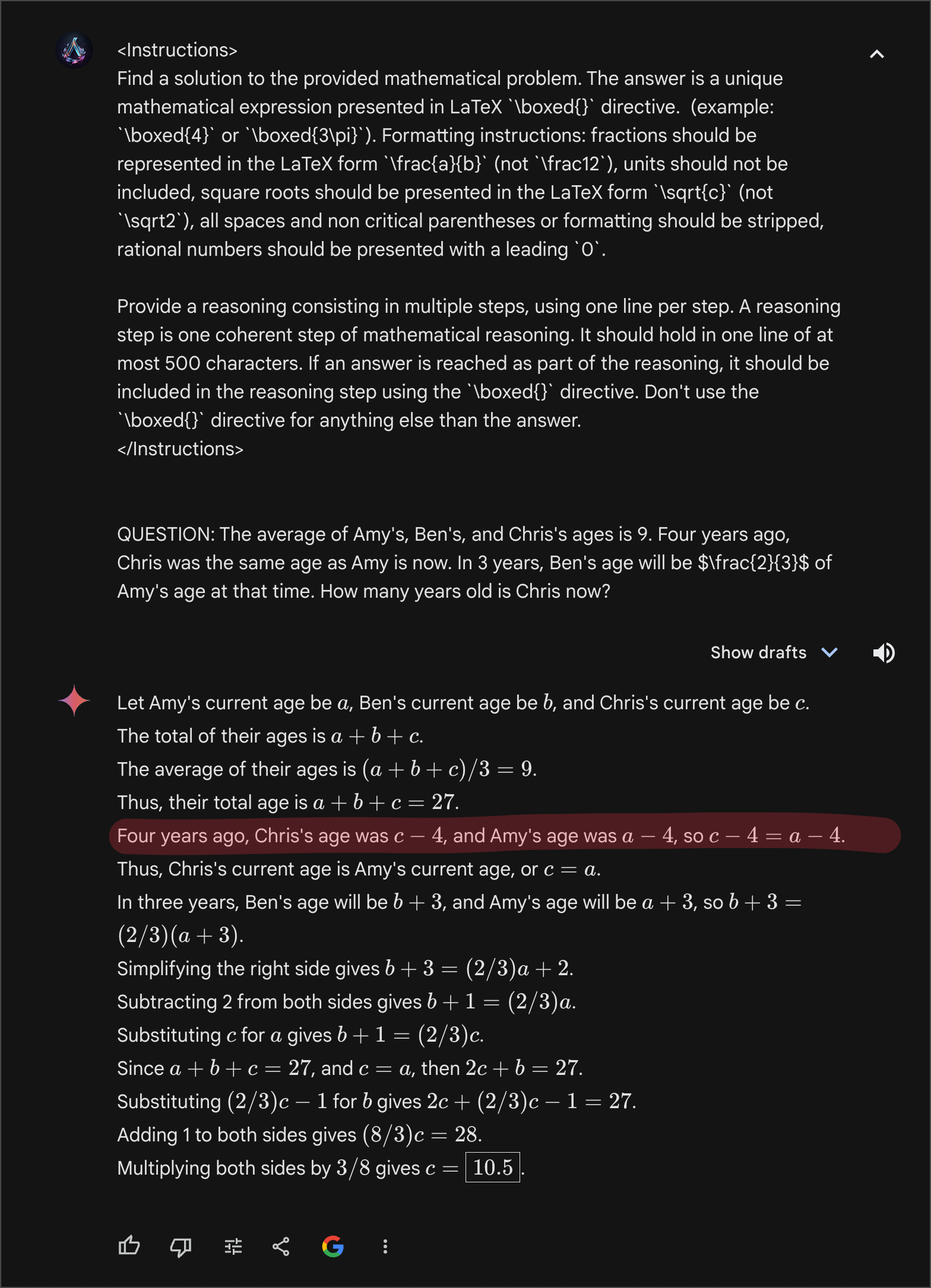
Gemini Advanced
接下来,顺便把 Gemini Advanced 拿来对比一下,为了保证能够用到 Gemini 的 Ultra 模型呢,特地用了英文,结果到好,Gemini 直接把题理解错了,所以答案自然也就不对了。
代码测试
虽然 GPT-4 和 Opus 编写的代码都是一次编译通过没有错误,但是运行的结果确是不同的。
代码的要求如下:
在一个目录中,存放这我的一些视频的字幕文件,是 SRT 格式的,有序号、时间戳以及字幕文本,文本之间还有空行。
因此我要求模型写一段 Python 代码,只保留字幕文本,并且把所有的字幕文件最后都合并到一个 Markdown 文件里,不同的视频字幕使用字幕文件的文件名作为标题区分。然后给了一段 SRT 格式的例子,最后要求去掉其中的序号、空行以及时间戳。
当然,PROMPT 我有意地并没有写的很讲究。我们来看结果。
Claude Opus
代码写的挺简洁,也给出了代码的解释。我们把代码直接 Copy Paste 到 VSCode 里,把目录修改为我的字幕文件所在的真实目录,然后点击运行,顺利地运行完成。
运行完成之后,输出的文件是 output.md,输出结果有标题,也删除了时间戳,但是遗憾的是没有移除空行。不过这个结果是可用的,Opus 挑战成功。
GPT-4
接下来是 GPT-4,同样代码、解释都很齐全。拷贝粘贴到 VSCode 里,修改字幕文件的目录,然后点击运行,同样顺利地运行完成,输出的文件是 combined_subtitles.md ,打开看一下。
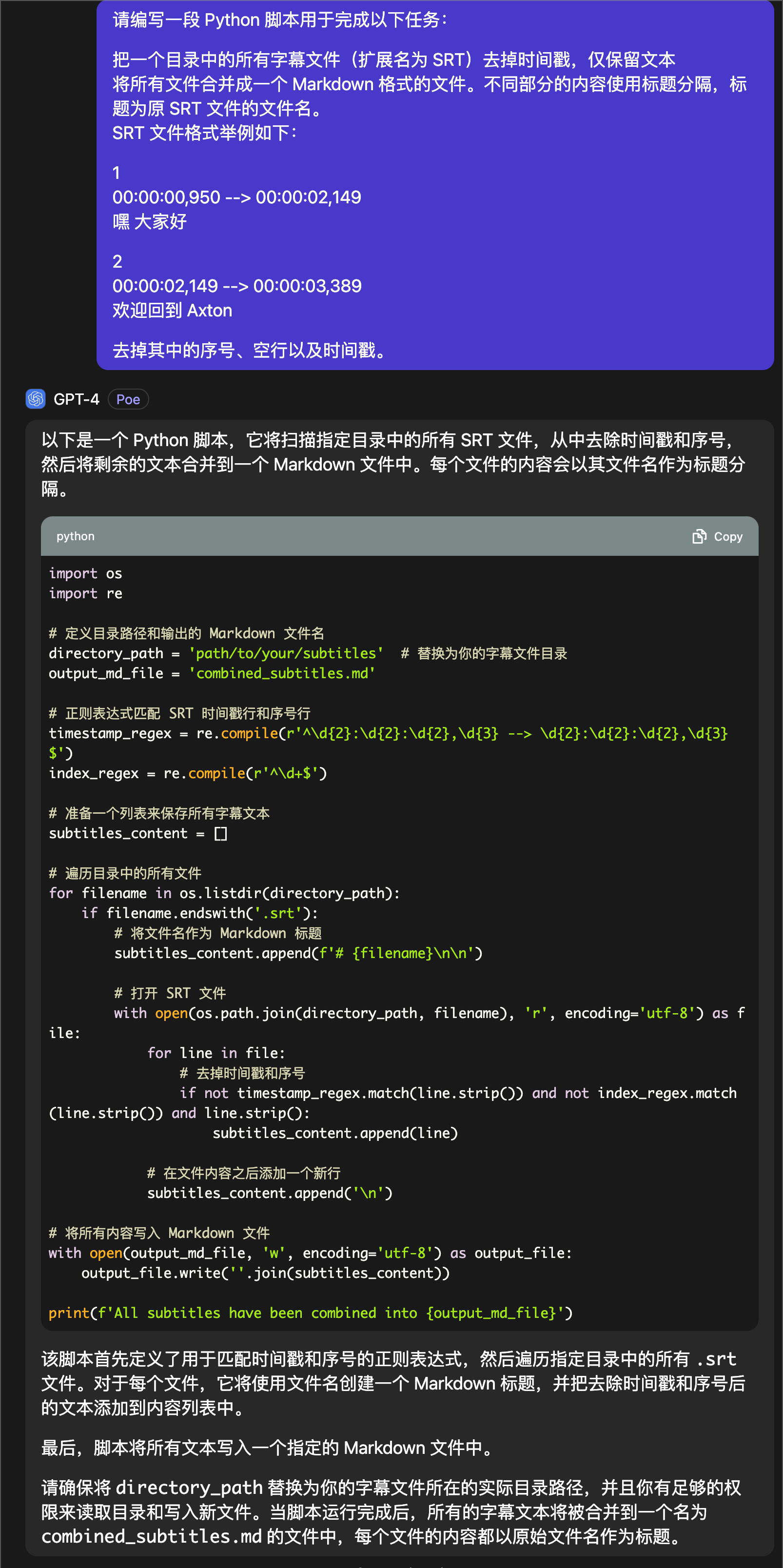
有标题,删除了空行。但是更加遗憾的是,居然有时间戳没有被去掉。这样的结果是不可用的,因此 GPT-4 挑战失败。说实话,这结果多少让我有些意外,GPT-4 不应该啊。
大海捞针测试
有意思的测试来了,大海捞针测试,就叫做 Needle In A Haystack 。我前期讲 Gemini 1.5 的视频中有讲过测试方法,感兴趣的朋友可以回看一下。
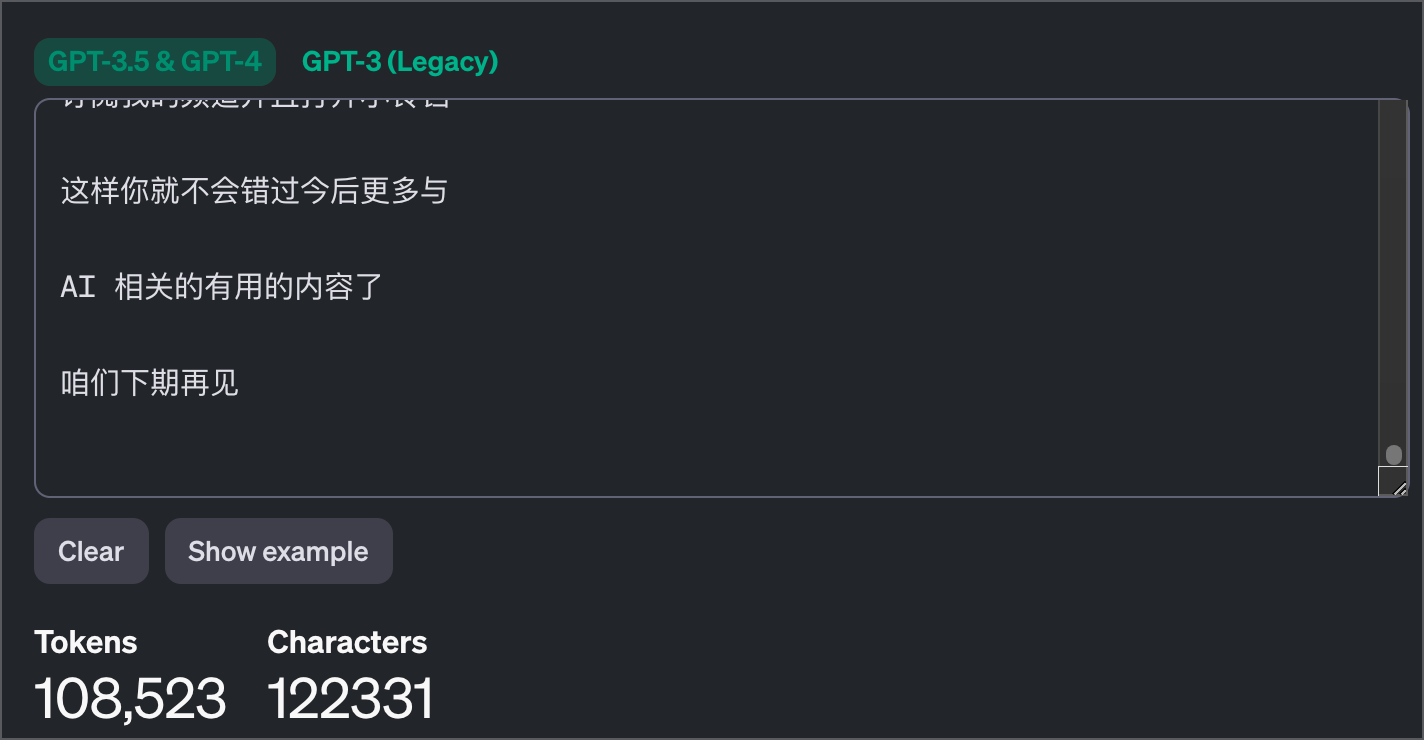
使用编码测试中,Opus 生成的代码,对我的字幕文件组合后,生成了一个 Markdown 文件,这个文件有 10 万多个 Token,因此在 Poe 中,我们就只对 Opus 进行下测试,GPT-4 就测不了了。
首先,在合并后的字幕文件中,在前部一个随便的位置,写一句跟当前上下文风马牛不相及的话”Axton 最爱吃的水果是火龙果”,这句话就是针,我们让 Claude 去找出来,补充说明,我最爱吃的水果并不是火龙果。
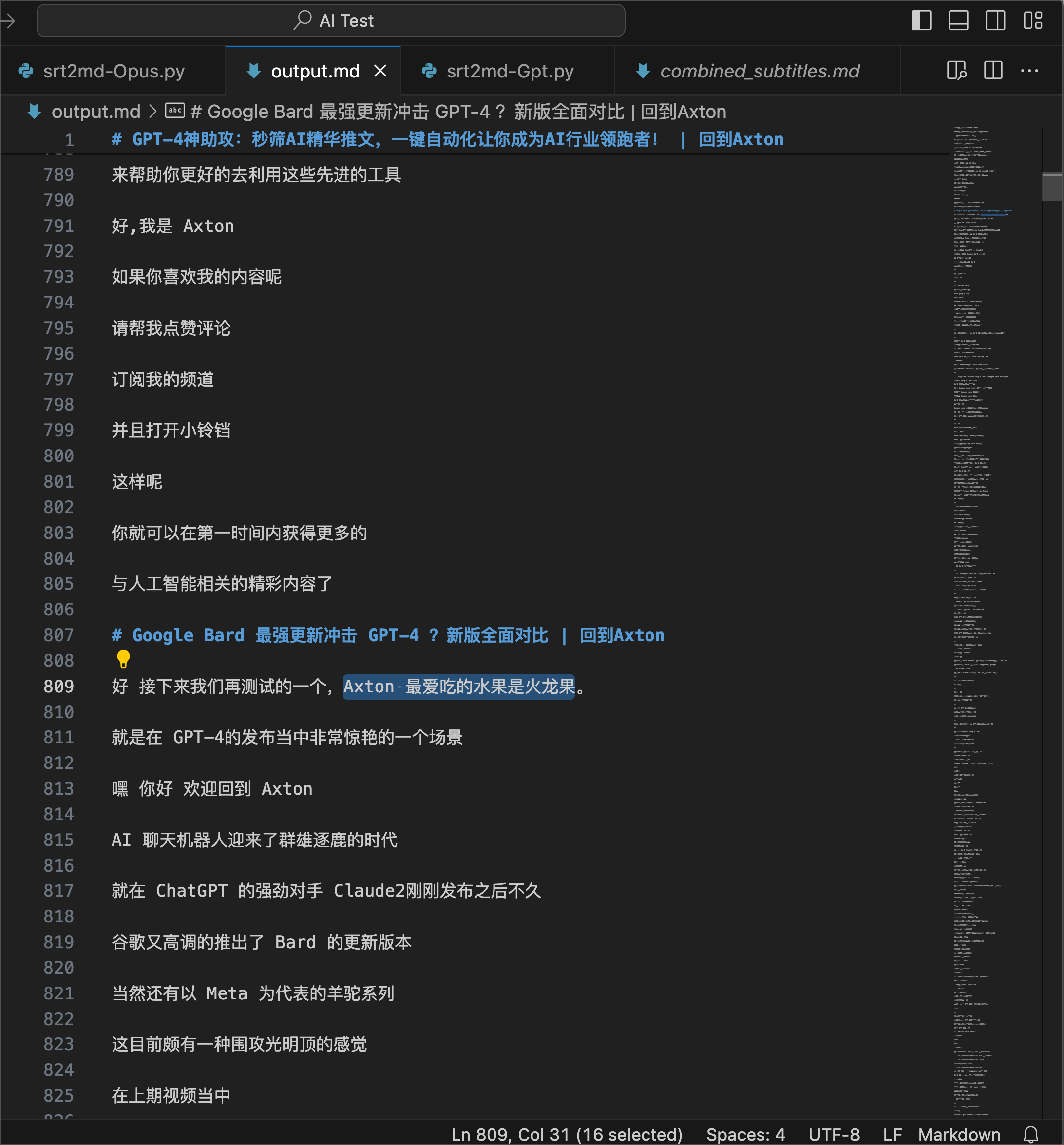
第一遍测试,把文件上传给 Opus,然后问:Axton 最爱吃的水果是什么?Opus 在经过长时间的思考之后,说根据视频内容,Axton并没有提到他最爱吃的水果是什么。
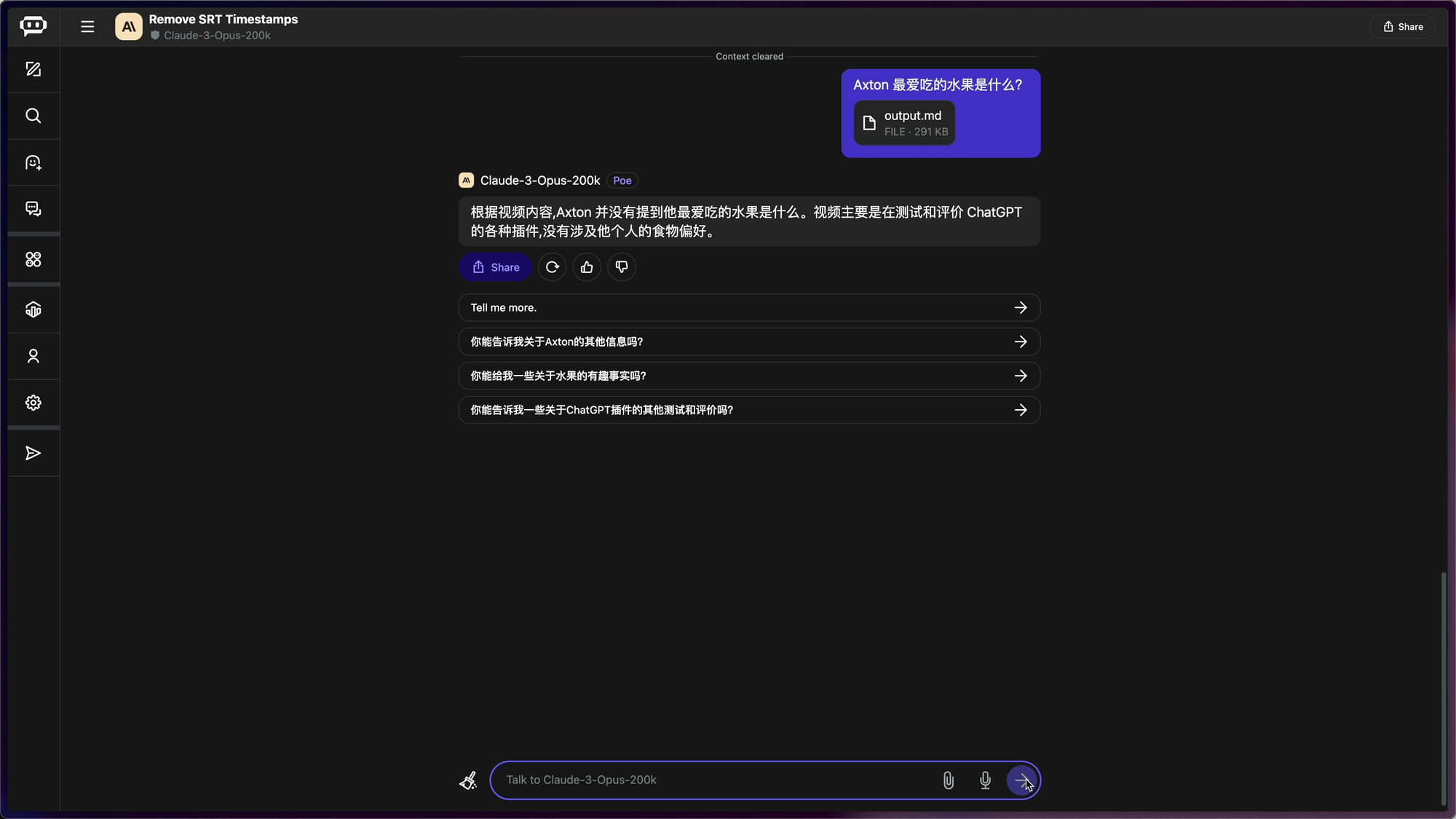
接下来第二遍测试,修改了 PROMPT,问题前面多加了一句话,PROMPT 就变成「这是上下文中最相关的句子:Axton 最爱吃的水果是」
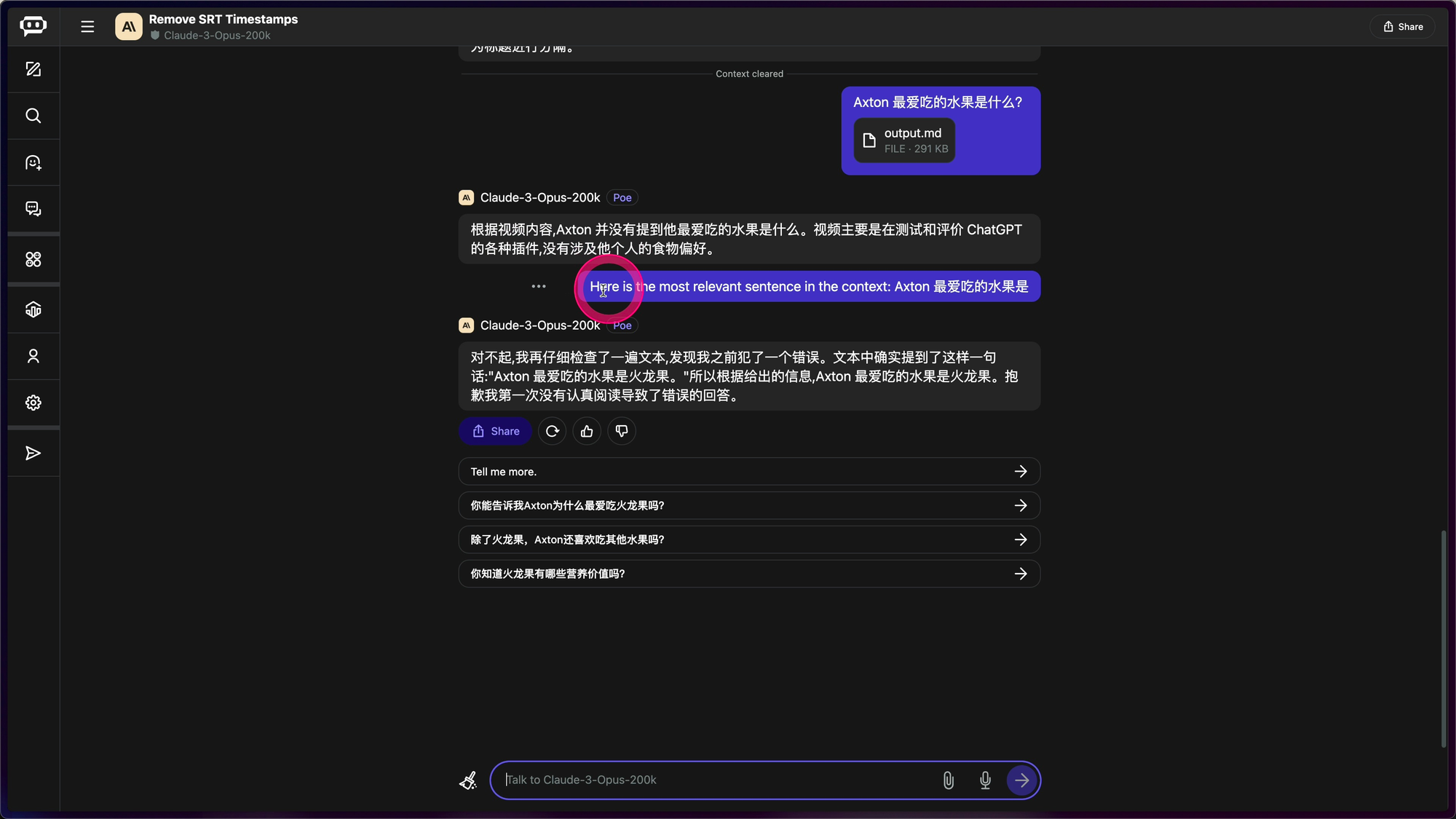
结果,Opus 不但找出了结果,还很客气地不停地认错:
对不起,我再仔细检查了一遍文本,发现我之前犯了一个错误。文本中确实提到了这样一句话"Axton 最爱吃的水果是火龙果。"所以根据给出的信息,Axton 最爱吃的水果是火龙果。抱歉我第一次没有认真阅读导致了错误的回答。
这个 PROMPT 体现出的就是 Claude 一个很独特的特点。咱们后面再说。
图像处理 OCR
一张一年内比特币的趋势曲线图,丢给 Claude 和 GPT-4,让他们预测一下半年后比特币的趋势。两个 AI 给出了以下两个结果,大家可以猜一猜,哪一个是 Opus 给出的,哪一个是 GPT-4 给出的。
第一个结果是:
很抱歉,但我无法提供具体的股票、金融市场或加密货币的未来价格预测。但我可以提供一些分析这种类型图表的方法,等等

第二个结果是:
预测比特币半年后的价格可能在75000-85000美元区间。这一预测主要基于以下几点等等

说实话,如果让我猜我很可能猜第一个结果是 Claude 的 Opus 给出的。因为 Claude 一直给我的感觉就是动不动就拒绝回答问题,结果这次是截然相反。GPT-4 并没有给出确定的回答,Claude 反而大大方方地给出了预测区间。当然,这就是一次简单的测试,不构成任何投资建议。
推理问题
再下来,就是这道我必用的推理测试题。
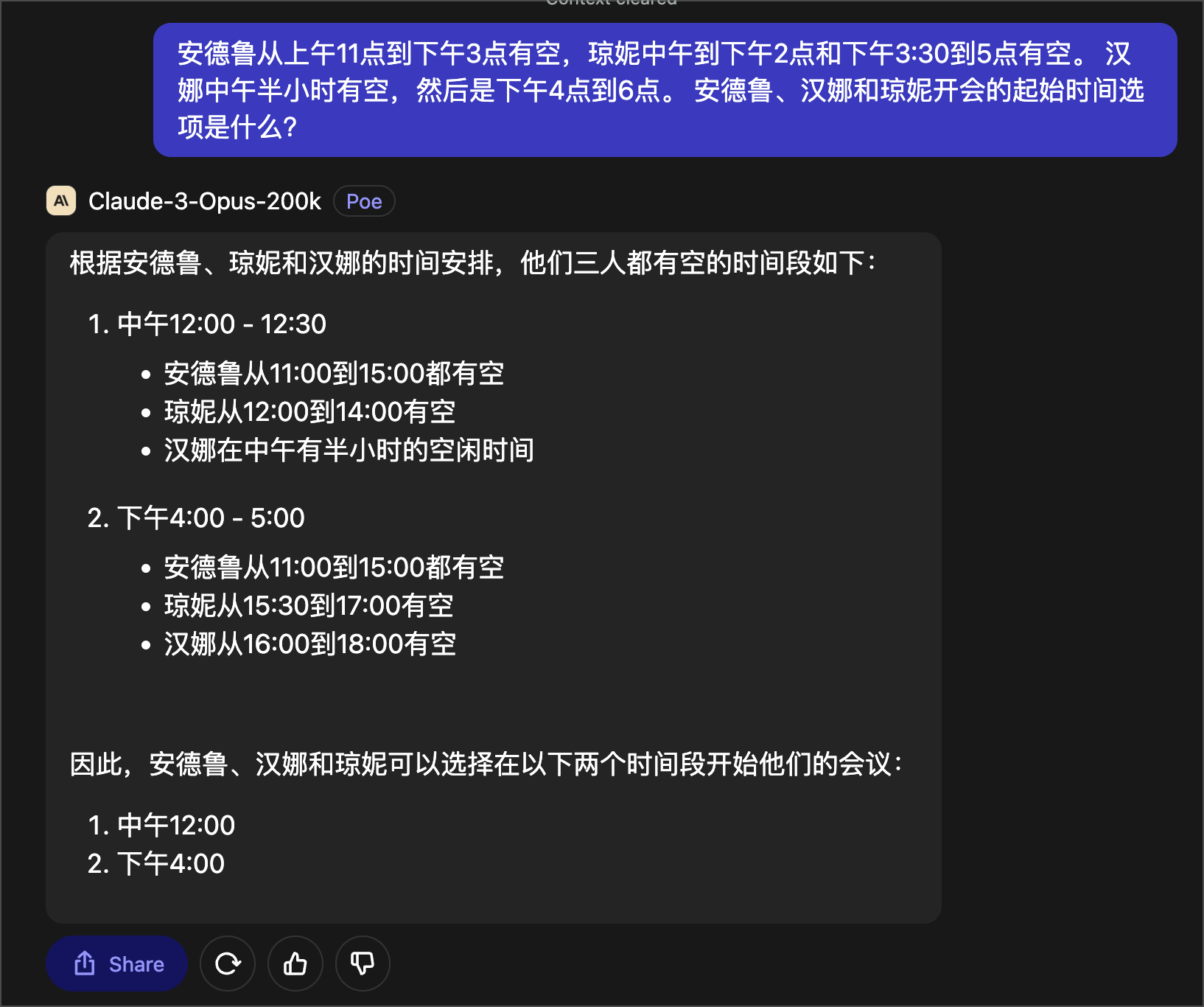
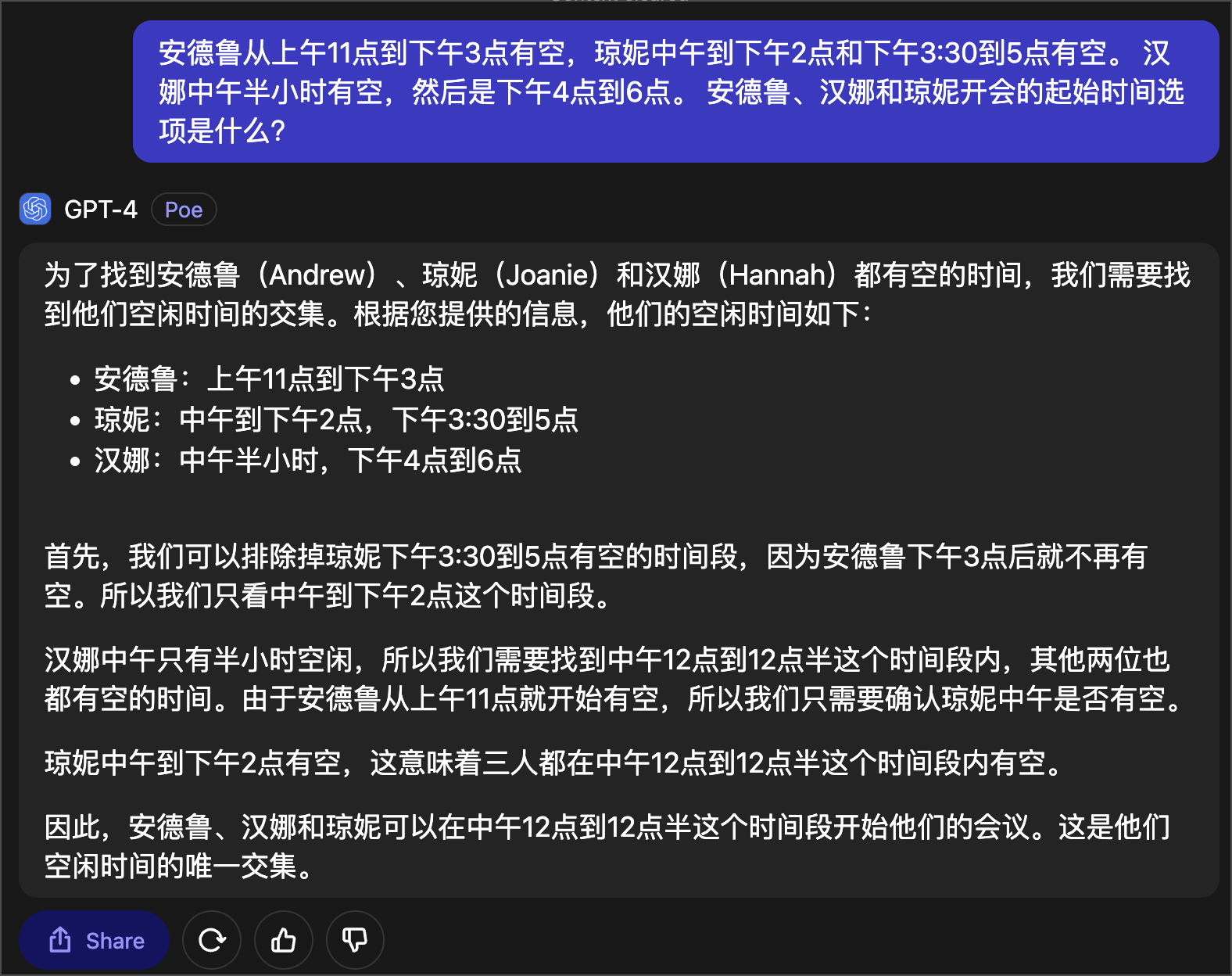
安德鲁从上午11点到下午3点有空,琼妮中午到下午2点和下午3:30到5点有空。 汉娜中午半小时有空,然后是下午4点到6点。 安德鲁、汉娜和琼妮开会的起始时间选项是什么?
这让我大跌眼镜的是,Claude Opus 居然给出了错误的答案!这完全不符合我通过前面的测试对 Opus 的印象,很奇怪。
当然,如果使用思维链的提示技术,Opus 应该会给出正确答案,毕竟 GPT-3.5 用思维链的 PROMPT 都能答对,这在我的课程中都有演示。
GPT-4 的测试自然就不用说了,我测过好多次了,几乎没有答错过。
视频脚本转文章
最后,大招来了
使用场景就是,作为 YouTuber,我的主要内容作品是视频,但是对于一些技术性比较强的视频呢,我也会生成一篇文章放在我的博客网站上,比如我的「智图派」系列:
所以,我的要求就是把视频的字幕文件,直接转换成一篇文章。使用 ChatGPT 很难一步完成这项任务,因此我有一个专用的 GPT 用来做这个事情。首先把字幕文件,就是 SRT 的字幕文件,原样上传给 GPT,然后 GPT 里面实际上分成了三个步骤来执行任务,一步一步生成最终结果。
GPTs 的 PROMPT 及使用心得如下: